GroupViT: Semantic Segmentation Emerges from Text Supervision
Abstract
Grouping and recognition are important components of visual scene understanding, e.g., for object detection and semantic segmentation. With end-to-end deep learning systems, grouping of image regions usually happens implicitly via top-down supervision from pixel-level recognition labels. Instead, in this paper, we propose to bring back the grouping mechanism into deep networks, which allows semantic segments to emerge automatically with only text supervision. We propose a hierarchical Grouping Vision Transformer (GroupViT), which goes beyond the regular grid structure representation and learns to group image regions into progressively larger arbitrary-shaped segments. We train GroupViT jointly with a text encoder on a large-scale image-text dataset via contrastive losses. With only text supervision and without any pixel-level annotations, GroupViT learns to group together semantic regions and successfully transfers to the task of semantic segmentation in a zero-shot manner, i.e., without any further fine-tuning. It achieves a zero-shot accuracy of 51.2% mIoU on the PASCAL VOC 2012 and 22.3% mIoU on PASCAL Context datasets, and performs competitively to state-of-the-art transfer-learning methods requiring greater levels of supervision.
Video
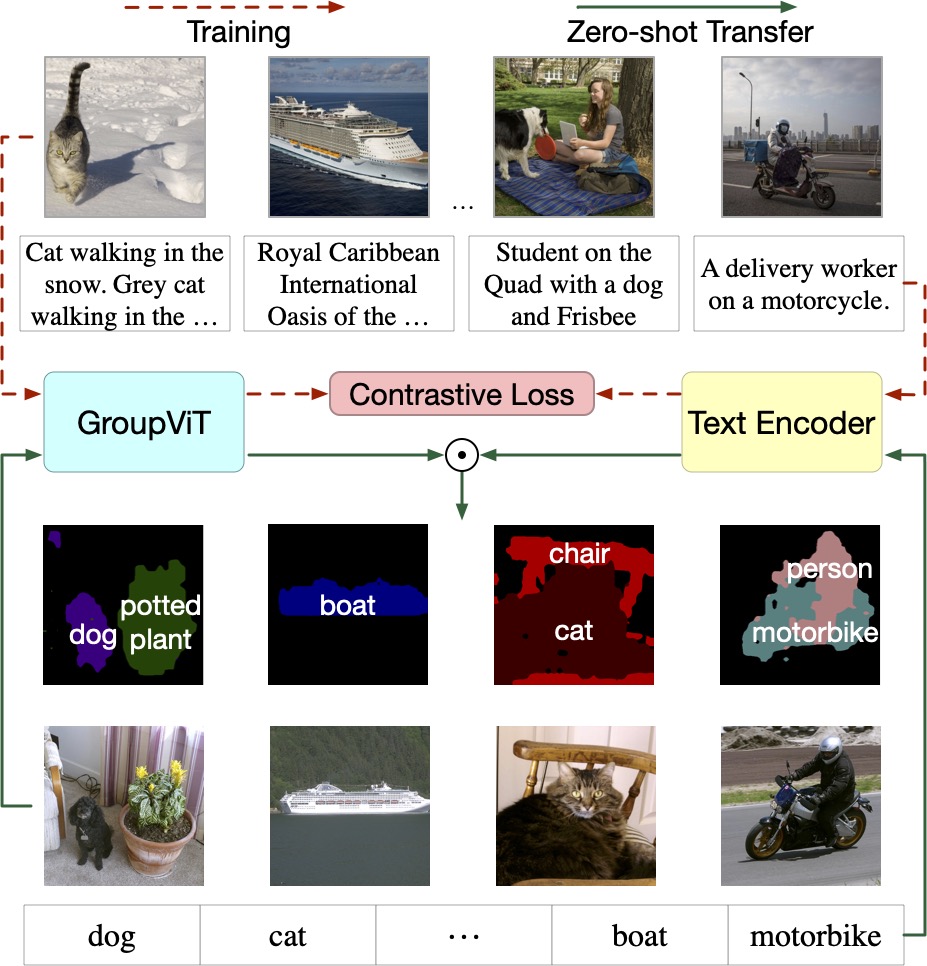
Problem Overview
First, we jointly train GroupViT and a text encoder using paired image-text data. With GroupViT, meaningful semantic grouping automatically emerges without any mask annotations. Then, we transfer the trained GroupViT model to the task of zero-shot semantic segmentation.
GroupViT Architecture
GroupViT contains a hierarchy of Transformer layers grouped into stages, each operating on progressively larger visual segments. The images on the right show visual segments that emerge during different grouping stages. The lower stage groups pixels into object parts, e.g., noses and legs of elephants; and the higher stage further merges them into entire objects, e.g., the whole elephant and the background forest. Each grouping stage ends with a grouping block that computes the similarity between the learned group tokens and segment (image) tokens. The segment tokens assigned to the same group are merged together and represent new segment tokens that are input to the next grouping stage.
Concepts Learnt by Group Tokens
We select some group tokens and highlight the attention regions across images in the PASCAL VOC 2012 dataset. Even there is no classification yet, different group tokens are learning different semantic concepts.
Results
We evaluate GroupViT on Pascal VOC, Pascal Context, and COCO datasets. GroupViT is not trained on any semantic segmentation annotation, and yet could zero-shot transfer to semantic segmentation classes of any dataset without fine-tuning.
Pascal VOC (zero-shot transfer without fine-tuning)
Click here for more results on Pascal VOC
Pascal Context (zero-shot transfer without fine-tuning)
Click here for more results on Pascal Context
COCO (zero-shot transfer without fine-tuning)
Click here for more results on COCO
BibTeX
@article{xu2022groupvit,
author = {Xu, Jiarui and De Mello, Shalini and Liu, Sifei and Byeon, Wonmin and Breuel, Thomas and Kautz, Jan and Wang, Xiaolong},
title = {GroupViT: Semantic Segmentation Emerges from Text Supervision},
journal = {arXiv preprint arXiv:2202.11094},
year = {2022},
}