IMProv: Inpainting-based Multimodal Prompting for Computer Vision Tasks
Abstract
In-context learning allows adapting a model to new tasks given a task description at test time. In this paper, we present IMProv- a generative model that is able to in-context learn visual tasks from multimodal prompts. Given a textual description of a visual task (e.g. “Left: input image, Right: foreground segmentation”), a few input-output visual examples, or both, the model in-context learns to solve it for a new test input. We train a masked generative transformer on a new dataset of figures from computer vision papers and their associated captions, together with a captioned large-scale image-text dataset. During inference time, we prompt the model with text and/or image task example(s) and have the model inpaint the corresponding output. We show that training our model with text conditioning and scaling the dataset size improves in-context learning for computer vision tasks by over +10% AP for Foreground Segmentation, over +5% gains in AP for Single Object Detection, and almost 20% lower LPIPS in Colorization. Our empirical results suggest that vision and language prompts are complementary and it is advantageous to use both to achieve better in-context learning performance.
IMProv Architecture
During training, the input image is patchified, masked, and fed to the model together with the associated caption CLIP embeddings. For each masked token, the decoder outputs a distribution over a frozen pretrained VQGAN codebook. The model is trained with cross-entropy loss.
S2CV dataset
We search result figures with captions in recent 12 years of computer vision papers, and use them as our training data. We perform random cropping in these figures and mask out parts of the images to perform inpainting task.
Qualitative Results
For each vision task X, we evaluate our model on two tasks - X-to-images and images-to-X.
Image -> Segmentation
Text prompt of the first example: "Left - input image, right - Semantic segmentation of save your life Grace..."










Image -> Edge
Text prompt of the first example: "Left - input image, right - Edge map of Small house..."









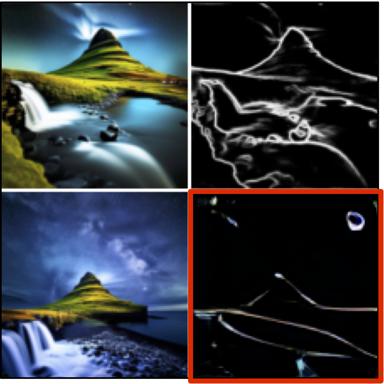
Image -> Depth
Text prompt of the first example: "Left - input image, right - Depth map in grayscale of THE CURATOR Carl by artist..."










Image -> Normal
Text prompt of the first example: "Left - input image, right - Normal map of ArtStation - Izumi Tanaka, Space Fligh..."










Segmentation -> image
Text prompt of the first example: "Right - output image of famous historic bell tower at the reschenpass - italy..."










Edge -> Image
Text prompt of the first example: "Right - output image of THE CURATOR Carl by artist Phil Paradise was painted in..."









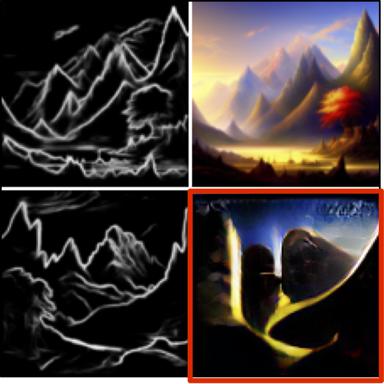
Depth -> Image
Text prompt of the first example: "Right - output image of left image, left - Depth map of righ..."










Normal -> Image
Text prompt of the first example: "Right - output image of sandstorm in desert and hiking man,illustration,digital..."










BibTeX
@article{xu2023improv,
author = {Xu, Jiarui and Gandelsman, Yossi and Bar, Amir and Yang, Jianwei and Gao, Jianfeng and Darrell, Trevor and Wang, Xiaolong},
title = {{IMProv: Inpainting-based Multimodal Prompting for Computer Vision Tasks}},
journal = {arXiv preprint arXiv: 2312.01771},
year = {2023},
}