Abstract
We present ODISE: Open-vocabulary DIffusion-based panoptic SEgmentation, which unifies pre-trained text-image diffusion and discriminative models to perform open-vocabulary panoptic segmentation. Text-to-image diffusion models have shown the remarkable capability of generating high-quality images with diverse open-vocabulary language descriptions. This demonstrates that their internal representation space is highly correlated with open concepts in the real world. Text-image discriminative models like CLIP, on the other hand, are good at classifying images into open-vocabulary labels. We propose to leverage the frozen representation of both these models to perform panoptic segmentation of any category in the wild. Our approach outperforms the previous state of the art by significant margins on both open-vocabulary panoptic and semantic segmentation tasks. In particular, with COCO training only, our method achieves 23.4 PQ and 30.0 mIoU on the ADE20K dataset, with 8.3 PQ and 7.9 mIoU absolute improvement over previous state of the art.
Video
Problem Overview
We propose to learn open-vocabulary panoptic segmentation with the internal representation of text-to-image diffusion models. K-Means clustering of the diffusion model's internal representation shows semantically differentiated and localized information wherein objects are nicely grouped together (middle figure). We leverage these dense and rich diffusion features to perform open-vocabulary panoptic segmentation (right figure).

ODISE Training Pipeline
ODISE leverages both text-to-image diffusion model and discriminative model to learn open-vocabulary panoptic segmentation. We first encode the input image into an implicit text embedding with an implicit captioner (image encoder \(\mathcal{V}\) and MLP). With the image and its caption as input, we extract their diffusion features from a frozen text-to-image diffusion UNet. With the UNet features, a mask generator predicts class-agnostic binary masks and their associated mask embedding features. We perform a dot product between the mask embeddings and text embeddings of training category names (red box) or nouns in the image caption (green box) to categorize them. The similarity matrix for mask classification is supervised by either cross entropy loss on the ground truth category label (red solid path), or via a grounding loss on the paired image captions (green dash path).
Qualitative Results
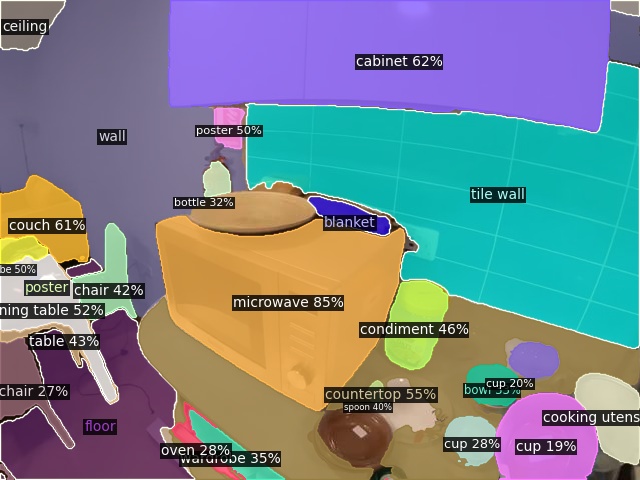
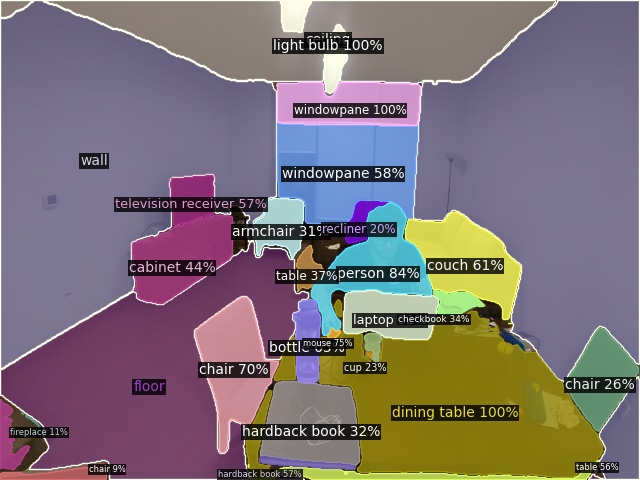
To demonstrate open-vocabulary recognition capabilities, we merge category names of LVIS, COCO, ADE20K together and perform open-vocabulary inference with \({\sim} 1.5k\) classes directly (hover to view the input image).
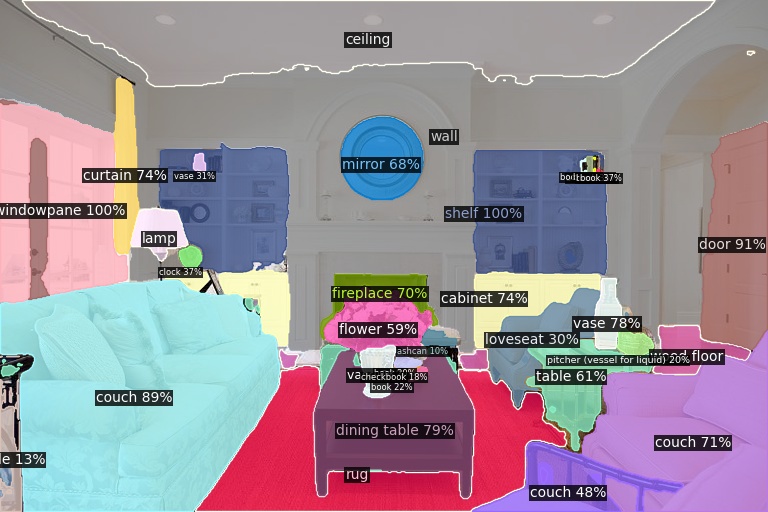
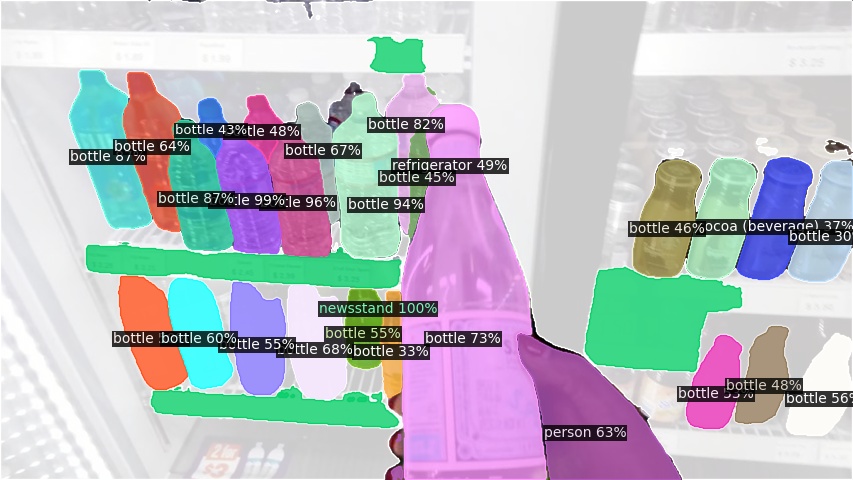
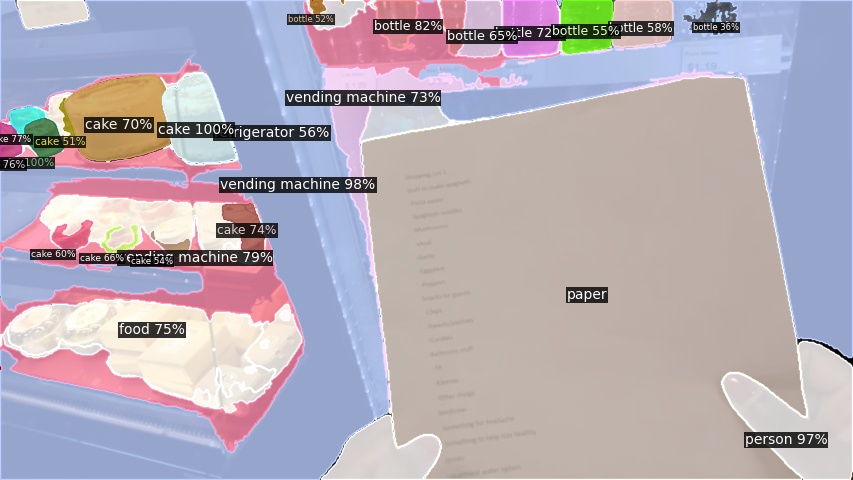
Open-Vocabulary Panoptic Segmentation on COCO
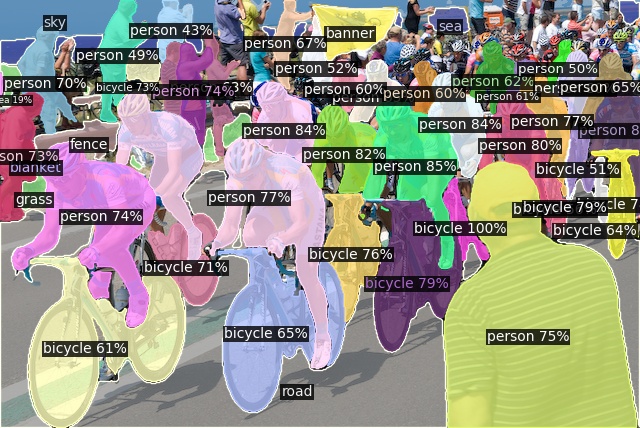

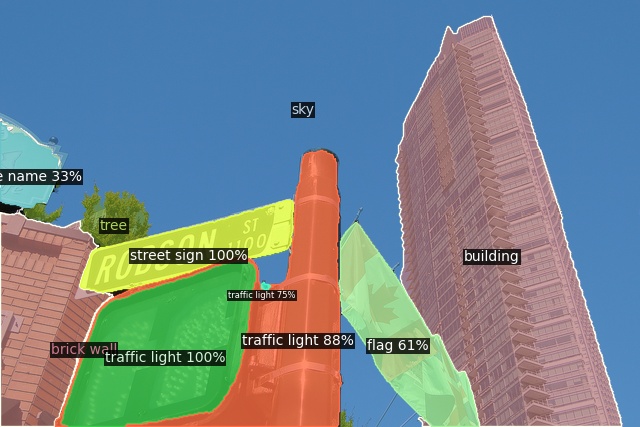



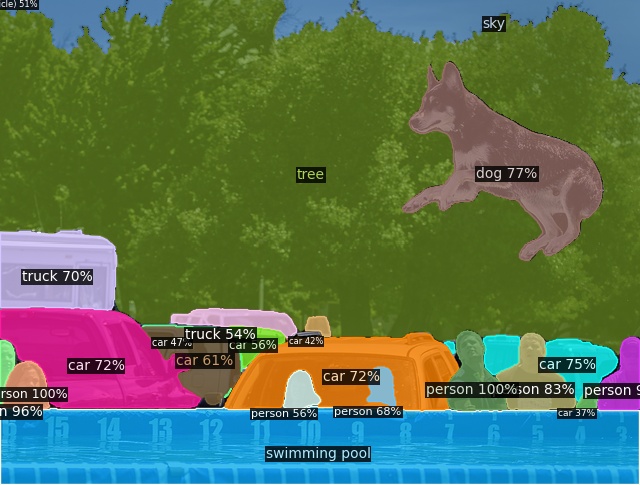

Click here for more results on COCO




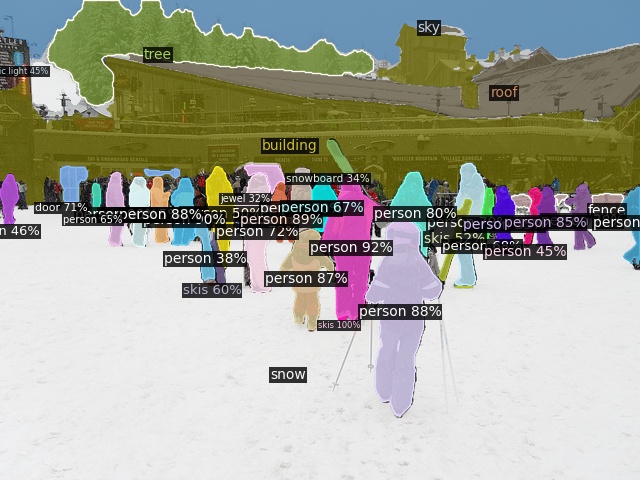

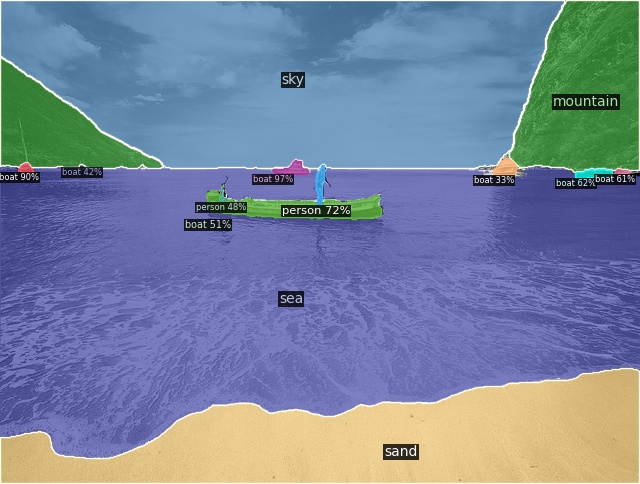

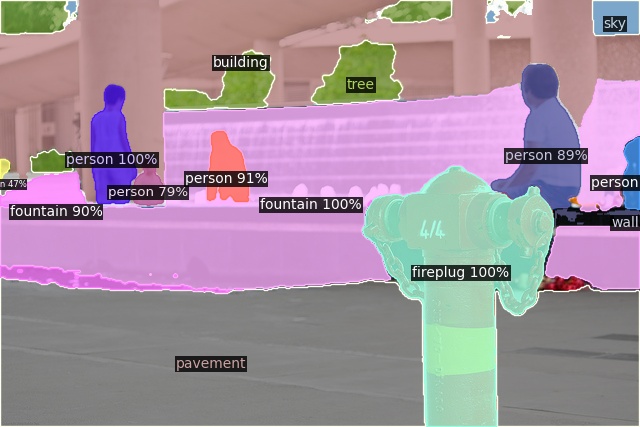

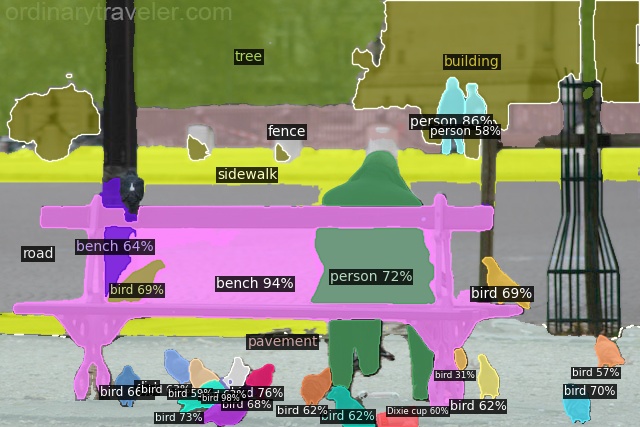



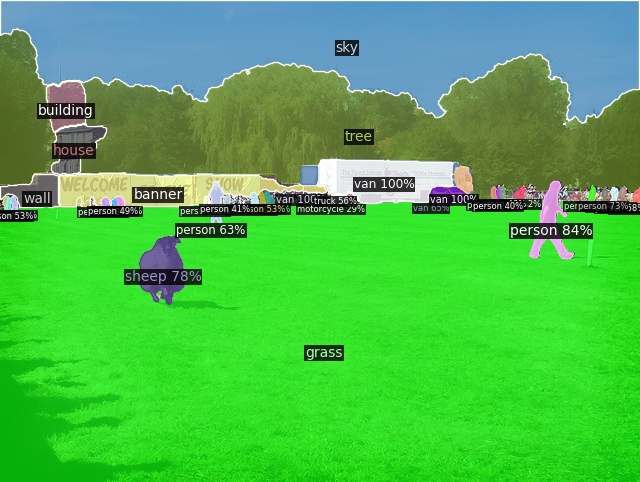

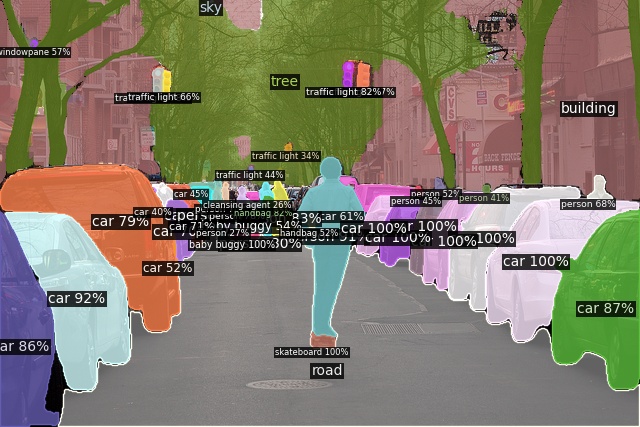

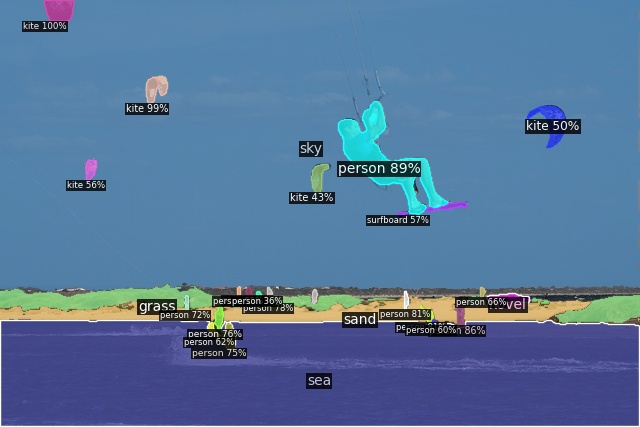

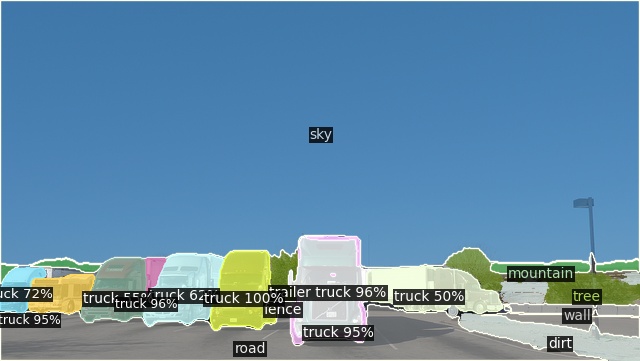



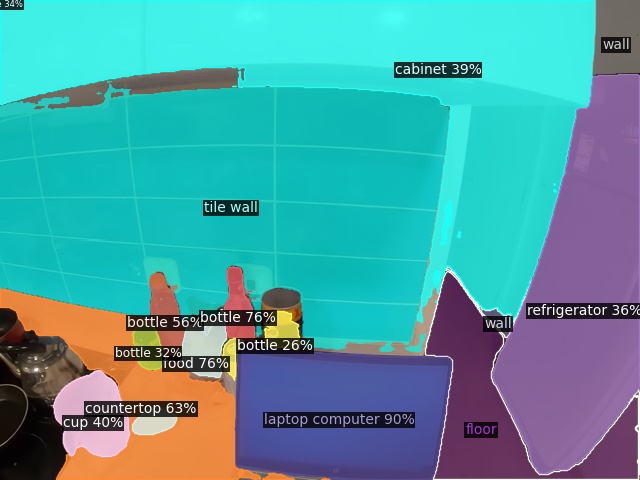
Open-Vocabulary Panoptic Segmentation on ADE20K


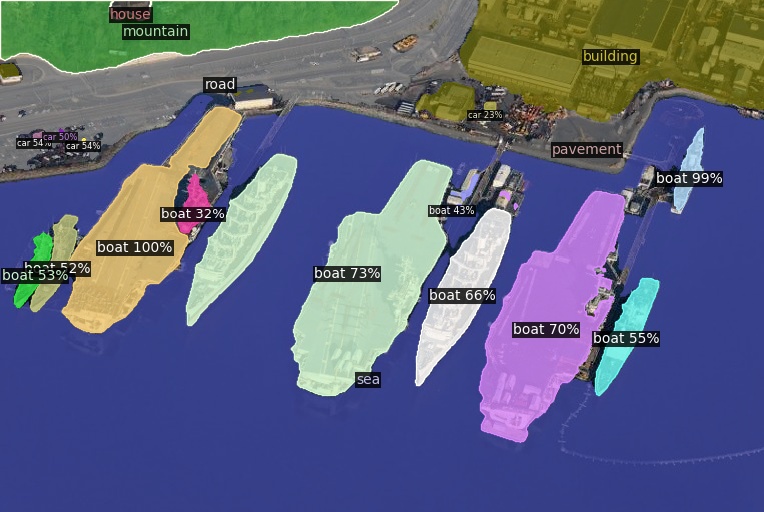

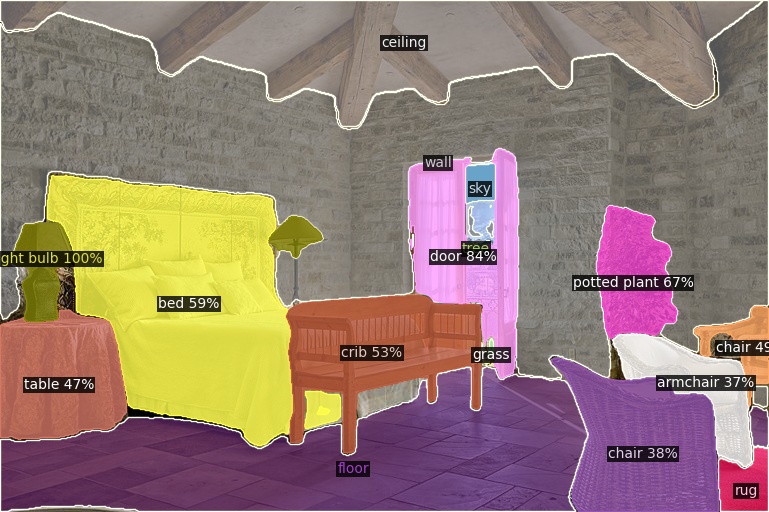



Click here for more results on ADE20K


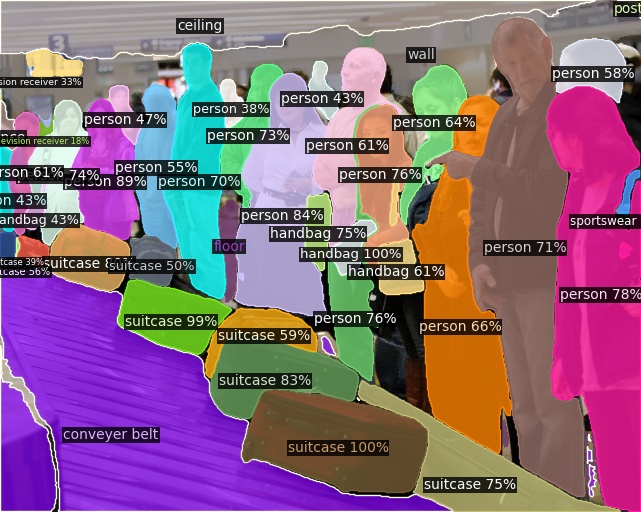





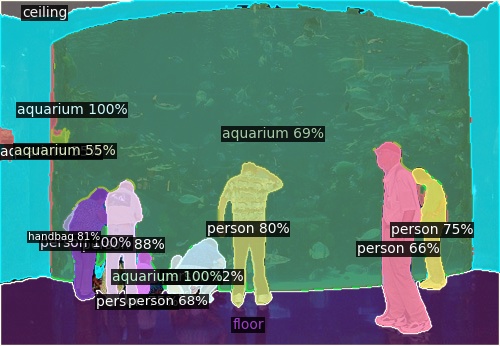






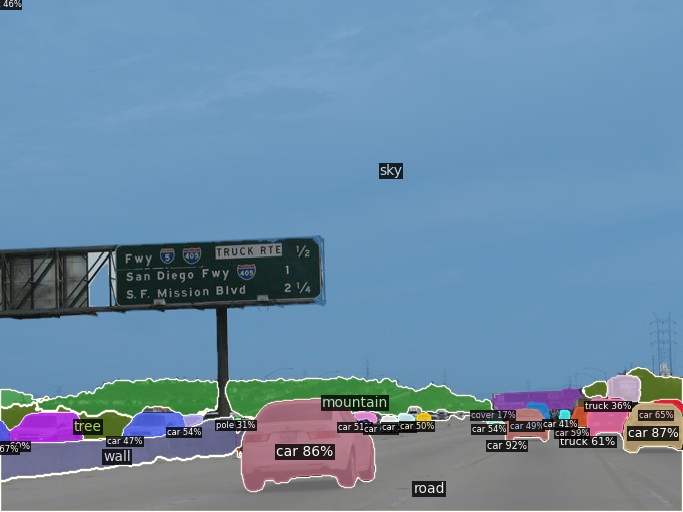



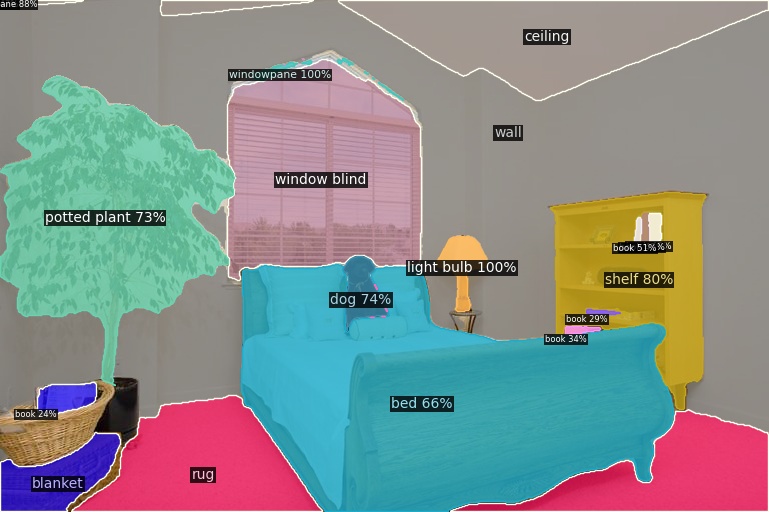



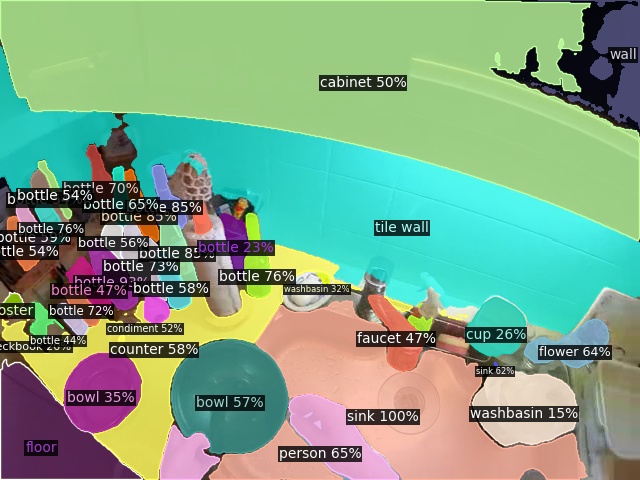
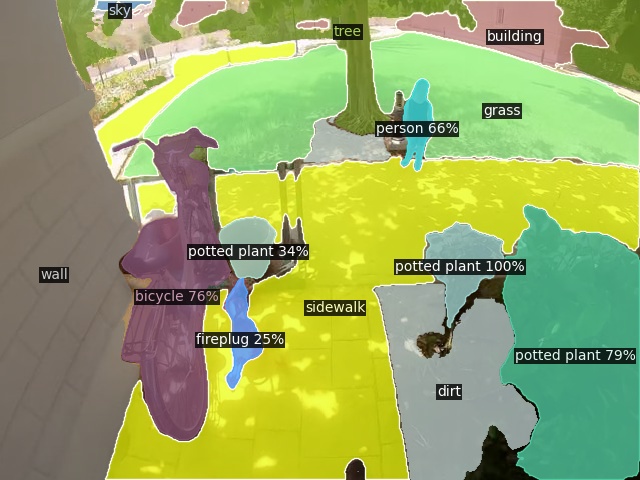
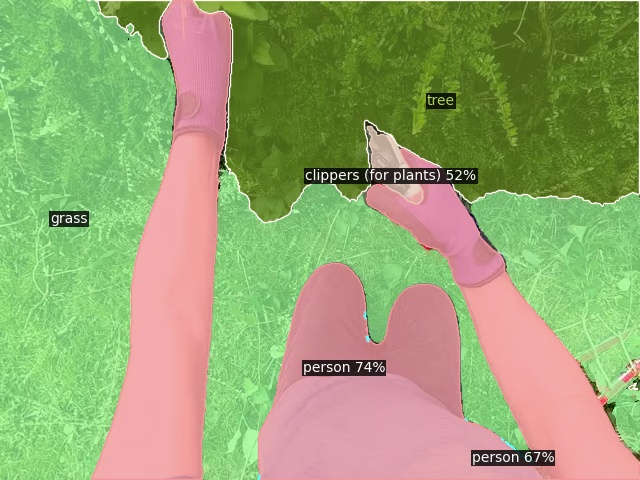
Open-Vocabulary Panoptic Segmentation on Ego4D
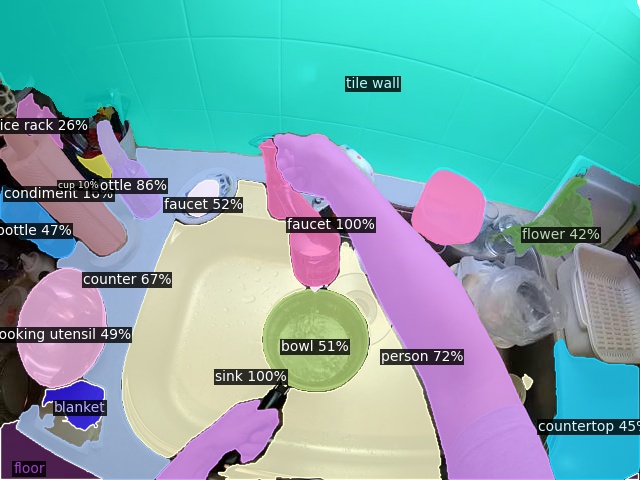

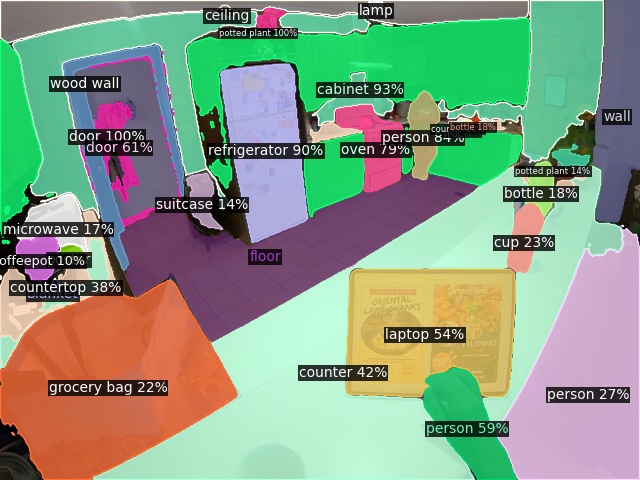

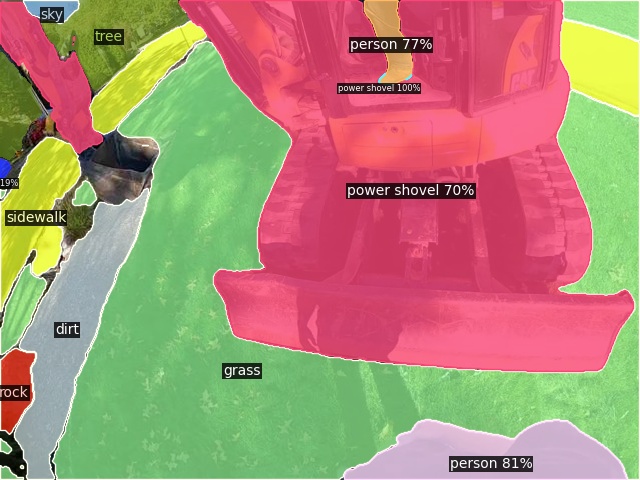

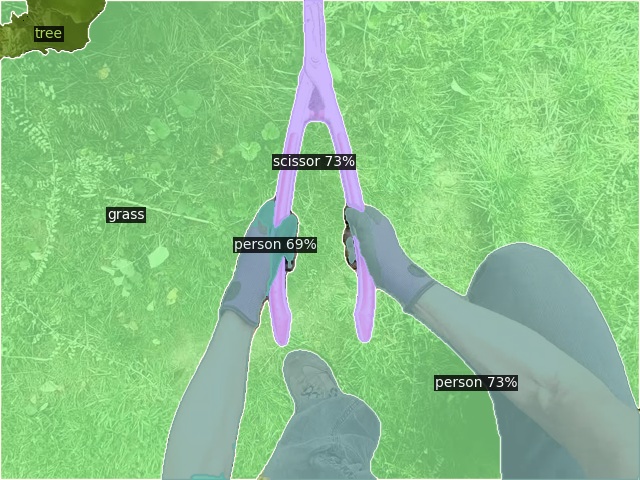

Click here for more results on Ego4D
















BibTeX
@article{xu2022odise,
author = {Xu, Jiarui and Liu, Sifei and Vahdat, Arash and Byeon, Wonmin and Wang, Xiaolong and De Mello, Shalini},
title = {{ODISE: Open-Vocabulary Panoptic Segmentation with Text-to-Image Diffusion Models}},
journal = {arXiv preprint arXiv: 2303.04803},
year = {2023},
}