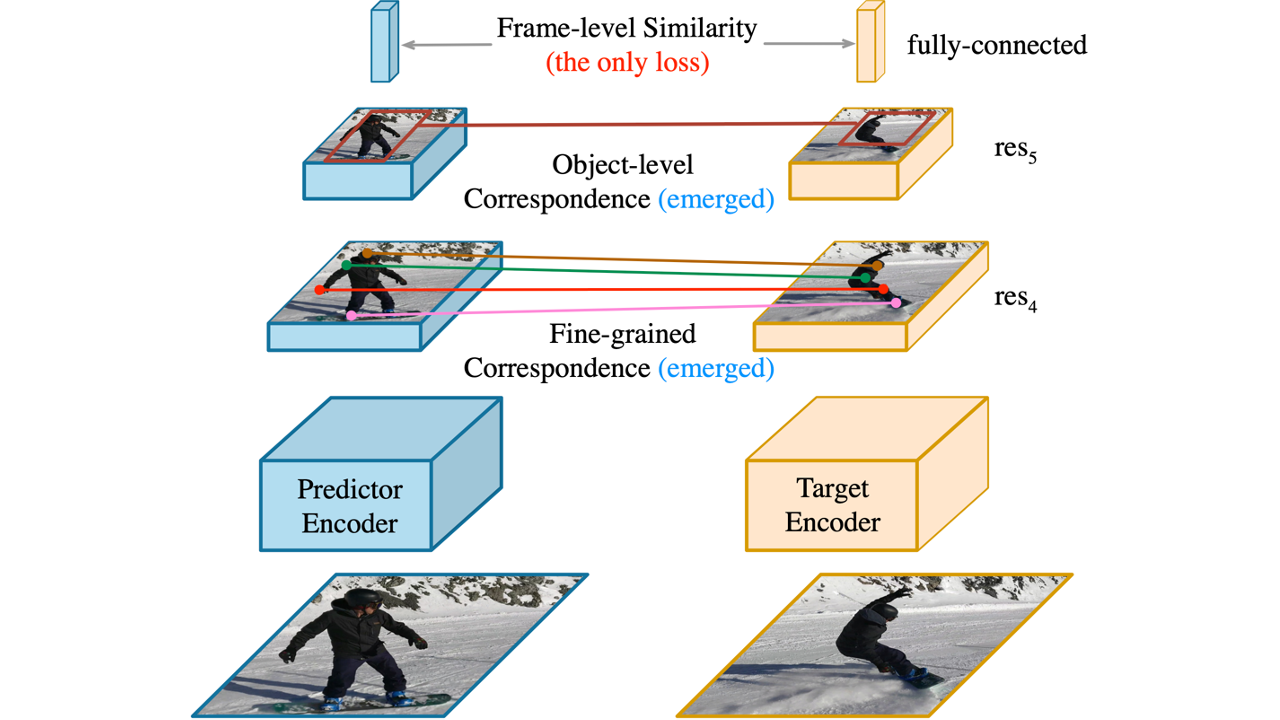
Learning a good representation for space-time correspondence is the key for various computer vision tasks, including tracking object bounding boxes and performing video object pixel segmentation. To learn generalizable representation for correspondence in large-scale, a variety of self-supervised pretext tasks are proposed to explicitly perform object-level or patch-level similarity learning. Instead of following the previous literature, we propose to learn correspondence using Video Frame-level Similarity (VFS) learning, i.e, simply learning from comparing video frames. Our work is inspired by the recent success in image-level contrastive learning and similarity learning for visual recognition. Our hypothesis is that if the representation is good for recognition, it requires the convolutional features to find correspondence between similar objects or parts. Our experiments show surprising results that VFS surpasses state-of-the-art self-supervised approaches for both OTB visual object tracking and DAVIS video object segmentation. We perform detailed analysis on what matters in VFS and reveals new properties on image and frame level similarity learning.
Oral Presentation
Fine-grained Correspondence
Fine-grained correspondence is evaluated on res4 feature map without fine-tuning.
DAVIS-2017 Video Object Segmentation




Object-level Correspondence
Object-level correspondence is evaluated on res5 feature map with fine-tuning.
OTB-100 Visual Object Tracking






More Fine-grained Correspondence
Fine-grained correspondence is evaluated on res4 feature map without fine-tuning.
VIP Human Part Segmentation




JHMDB Human Pose Tracking




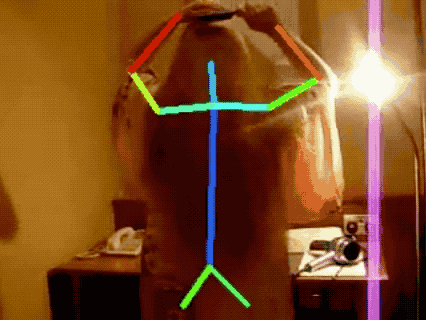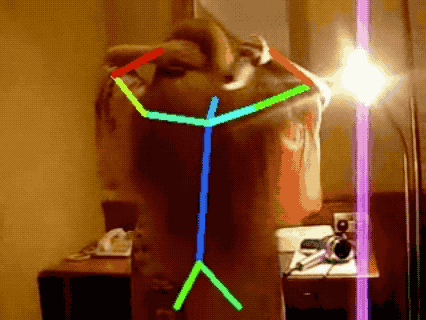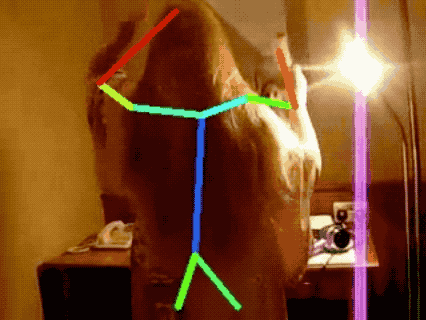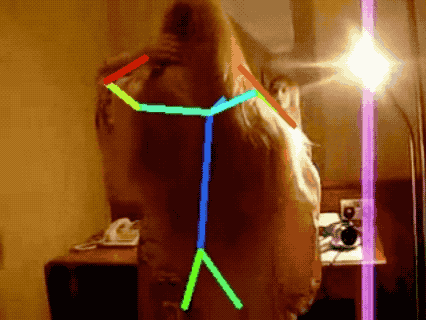

More results
Paper

BibTeX
@inproceedings{xu2021rethinking,
author = {Xu, Jiarui and Wang, Xiaolong},
title = {Rethinking Self-Supervised Correspondence Learning: A Video Frame-Level Similarity Perspective},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {10075-10085}
}